Running a Bitcoin node is one of the most meaningful contributions you can make to network sovereignty — but node operations sit in a technical no-man's-land. The problems are real, the logs are dense, and most debugging guides assume deep Linux expertise. This is exactly where AI vibe coding changes everything.
This guide documents a specific, repeatable methodology. Not a one-time trick — a systematic debugging loop you can apply to any Umbrel stability issue. The Bitcoin Tor case study is the proof it works.
The Problem: Tor Disconnects Every 24–36 Hours
The symptom was subtle at first — periodic connectivity drops that were brief enough to go nearly unnoticed. The node would reconnect, the wallet would sync, and everything appeared normal. But something was off. On closer inspection, the pattern was consistent: Tor connections resetting on a roughly 24–36 hour cycle.
This kind of intermittent, cyclical failure is the hardest class of bug to diagnose because it mimics so many other causes:
- ISP routing or NAT timeout policies
- Router firmware memory leaks
- Raspberry Pi thermal throttling or power fluctuation
- Specific Umbrel app conflicts consuming resources
- Tor guard node rotation behaviour
- A software bug in umbrel-bitcoin itself
The only way to distinguish between these is evidence — collected systematically, over time, with the variable space progressively narrowed.
₿ The core insight: The cycle length (24–36 hours) is the diagnostic key. It's too long to be a memory pressure issue (those manifest in hours), too consistent to be random network noise, and too short to be a guard node rotation (those happen over days). This regularity points to a timer or keepalive mechanism in software — not hardware.
Phase 1: Read-Only Investigation — The Foundation
The single most important rule in node debugging: observe first, change nothing. Every config change you make before establishing a baseline contaminates your evidence and makes the actual cause harder to find. This is where most node operators go wrong — they start changing settings before they have a clear hypothesis.
The approach here follows the three-phase vibe coding methodology:
Observe & Log
Collect terminal output, docker logs, and umbrel system logs. No changes. AI reads the data alongside you.
Pattern Recognition
Correlate timestamps across log sources. Identify the last event before each disconnect. Build a reproducible timeline.
Targeted Hypothesis
Only make changes once the pattern is conclusive. One change at a time. Document everything. Escalate if confirmed software.
The App Stack Isolation Process
The first systematic step was reducing the Umbrel app stack one application at a time — stopping each app and running the node for a full 48-hour observation window before drawing any conclusions. This rules out app-level resource conflicts:
-
Document your current app stack
Open a new markdown session file. List every installed Umbrel app with its version. This is your baseline. Paste this into your AI session as the first message of every new chat.
-
Stop apps in order of resource intensity
Start with the heaviest consumers: LND lightning node, Electrs, mempool.space. Run 48 hours between each stop. Do not stop multiple apps simultaneously — you lose the ability to attribute changes.
-
Log every observation window result
For each window: did the disconnect happen? What time? What was the last log entry before the reset? Append this to your session markdown. This is your evidence chain.
-
Continue until only umbrel-bitcoin + Tor remain
If the disconnect persists with only the base Bitcoin node running and no other apps, you have isolated the fault to the core stack. This is when the software hypothesis becomes the primary candidate.
The Session Markdown File — Your Most Important Tool
Every debugging session produces information. The problem is that AI models have no memory between conversations — every new chat starts from zero. Without a persistent record, you repeat yourself constantly, and the AI can't help you spot patterns that span multiple days.
The solution is a session markdown file — a running document you maintain throughout the investigation. When you start a new AI session, your first message is always: paste this file, here's what happened since the last update.
# Node Debug Session — umbrel-bitcoin Tor Stability ## Node Info - Hardware: [Raspberry Pi 4 8GB / Intel NUC / etc.] - Umbrel version: [x.x.x] - umbrel-bitcoin version: [x.x.x] - Connection: Fibre / Cable / [ISP] - Tor mode: Automatic / Bridge ## Current Hypothesis [Update this every session — what do you think is causing it?] ## App Stack (at session start) - Bitcoin Core ✓ - LND ✓ / stopped [date] - Electrs ✓ / stopped [date] - [other apps] ## Disconnect Log | Date | Time | Interval since last | Last log before reset | Notes | |------------|-------|---------------------|-----------------------|-------| | 2026-04-01 | 14:22 | — | tor[xxx]: Timeout | First observed | | 2026-04-02 | 16:05 | 25h 43m | tor[xxx]: Timeout | LND still running | | 2026-04-03 | 17:31 | 25h 26m | tor[xxx]: Timeout | LND stopped, same pattern | ## What I've Tried - [ ] Stopped LND — disconnect persisted (25h interval) - [ ] Stopped Electrs — disconnect persisted (26h interval) - [ ] Restarted router — disconnect persisted next cycle - [ ] Changed Tor circuit timeout in torrc — no effect ## Commands Run This Session ``` docker logs umbrel_tor_1 --since 48h > tor_48h.log docker logs umbrel_bitcoin_1 --since 48h > btc_48h.log umbrel app logs bitcoin ``` ## Current Evidence Summary [Summarize what you know so far — paste AI's last analysis here] ## Next Steps [What you plan to do in the next 48-hour window]
🔑 The restart rule: Always start a new AI session by saying: "Here is my current debugging session file for an Umbrel Bitcoin node Tor issue. Using only this context, what patterns do you see and what would you check next?" This keeps the AI grounded in your actual evidence rather than giving generic troubleshooting advice.
Key Log Commands for Umbrel Bitcoin Debugging
These are the read-only commands that form the core of the investigation. Run these, save the output to files, and feed them to AI for analysis.
# Full Tor container logs — last 48 hours docker logs umbrel_tor_1 --since 48h --timestamps 2>&1 | tee tor_48h.log # Bitcoin Core logs — last 48 hours docker logs umbrel_bitcoin_1 --since 48h --timestamps 2>&1 | tee btc_48h.log # All Umbrel app logs at once umbrel app logs bitcoin umbrel app logs lightning # if LND installed # System resource snapshot docker stats --no-stream # Check Tor circuit status docker exec umbrel_tor_1 cat /var/lib/tor/state | grep -i "lastwritten\|guard" # Disk and memory pressure check df -h && free -h # Check for any OOM kills in system journal journalctl -k | grep -i "oom\|killed" | tail -20
What to Feed AI After Collecting Logs
I am debugging persistent Tor disconnects on an Umbrel Bitcoin node. The pattern is a consistent 24–36 hour reset cycle. Here is my session log file showing the investigation history: [PASTE SESSION MARKDOWN] Here are the latest docker logs from tor and bitcoin containers (48h window): [PASTE tor_48h.log] [PASTE btc_48h.log] Using only the evidence in these logs, please: 1. Identify the exact timestamp and log entry immediately before each disconnect 2. Look for any pattern in what triggers the Tor circuit reset — is it a timeout value, a keepalive failure, or an external event? 3. List any log entries that repeat on a ~24–36 hour schedule regardless of disconnect 4. Tell me the single most likely root cause based purely on what you can see 5. Suggest the next ONE thing I should check — read-only only, no config changes yet
Choosing the Right AI Model for Node Debugging
Not all AI models perform equally well for this kind of systematic log analysis. The choice of model matters — and counterintuitively, maximum thinking modes are often worse for log triage.
| Model / Mode | Best Use in This Workflow | Why |
|---|---|---|
| Claude Sonnet (medium) | Daily log analysis, pattern spotting, session summaries | Practical, grounded in your data. Doesn't invent explanations not in the logs. |
| Claude Opus (high) | Synthesising 2+ weeks of evidence into a unified hypothesis | Worth the extra latency when you have a large evidence base and need deep cross-correlation. |
| ChatGPT GPT-5.5 | GitHub issue drafting, cross-checking with public Umbrel issues | Strong at referencing known patterns from its training data on open-source projects. |
| DeepSeek-V3 | Docker/Linux command generation, torrc config analysis | Excellent at low-level system and networking specifics. |
| Extended thinking / o3 | Avoid for routine log reads | Tends to over-engineer simple timing patterns. Practical medium models outperform here. |
₿ The model rotation principle: Run the same log dump through two different models in separate sessions. If both point to the same component independently, your confidence in that hypothesis increases significantly. Disagreement between models is a signal that you need more data — not that one model is right.
When Things Go Wrong: The Docker Change & Backup Restore
⚠️ This section documents a critical lesson: After two weeks of read-only investigation and inconclusive results, an experimental Docker configuration change was attempted. It crashed the system, left the node unresponsive, and required a full backup restore. This was a mistake — and a valuable one.
The lesson: do not make destructive changes until your evidence is conclusive and your hypothesis is specific. If you find yourself "trying things," your evidence base isn't strong enough yet. Go back to observation.
What the Backup Restore Revealed
The forced restore was not entirely a loss. Running a full Bitcoin Core re-sync from backup (approximately half a day on fibre) stress-tested the backup system in a way that scheduled tests never do. Key observations:
- 12 Lightning channels were force-closed during the restore — an expected consequence of the node going offline uncleanly. Funds eventually returned to the on-chain wallet, confirming the LND breach remedy and HTLC resolution mechanisms functioned correctly.
- The full blockchain re-sync completed without errors, validating the integrity of the backup snapshot.
- The Tor disconnect pattern resumed immediately after restore on the same cycle — confirming this was not a corrupted state issue. It was software behaviour.
⚡ On force-closed channels: Fund recovery after force closure is not immediate — it follows the CSV (CheckSequenceVerify) delay encoded in your channel scripts, typically 144–2016 blocks (~1–14 days). If you must restore, account for this timeline and do not panic if funds are not immediately visible in your on-chain wallet.
Paradoxically, the backup restore provided the single most useful piece of evidence: the disconnect pattern survived a complete state wipe and re-sync. Hardware, local state, and app conflicts were definitively eliminated. This was a software bug in the Umbrel Bitcoin stack, not local to the specific installation.
Building the Evidence Case: Week Three
After the restore, the investigation continued for another week. By this point the session markdown file had grown into a comprehensive record covering:
- Multiple confirmed disconnect events with exact timestamps across each observation window
- Consistent interval: 24h 50m ± 45 minutes across all events
- The precise Tor log entry immediately preceding every disconnect
- Confirmed elimination of: hardware, ISP, router, LND, Electrs, mempool.space, system resources, and local state
- Cross-referenced against public Umbrel community reports showing similar patterns from other node operators
The AI's analysis of this consolidated evidence pointed to the Tor connection keepalive timeout configuration within the umbrel-bitcoin Docker container — a value that was triggering a full circuit teardown rather than a graceful reconnect at the 24–36 hour mark.
🔑 The evidence threshold: You know you have enough evidence to escalate when: (1) you can predict the next disconnect within a 2-hour window, (2) you have eliminated all local variables, and (3) you have logs showing the same final entry before every event. If you can't predict it, you don't understand it yet.
Filing the GitHub Issue: How to Get a Same-Day Response
The quality of a bug report determines whether developers can act on it immediately or must spend hours asking follow-up questions. The goal is to make the path from "read your report" to "reproduce and fix" as short as possible. This is where AI becomes a writing partner, not just an analyst.
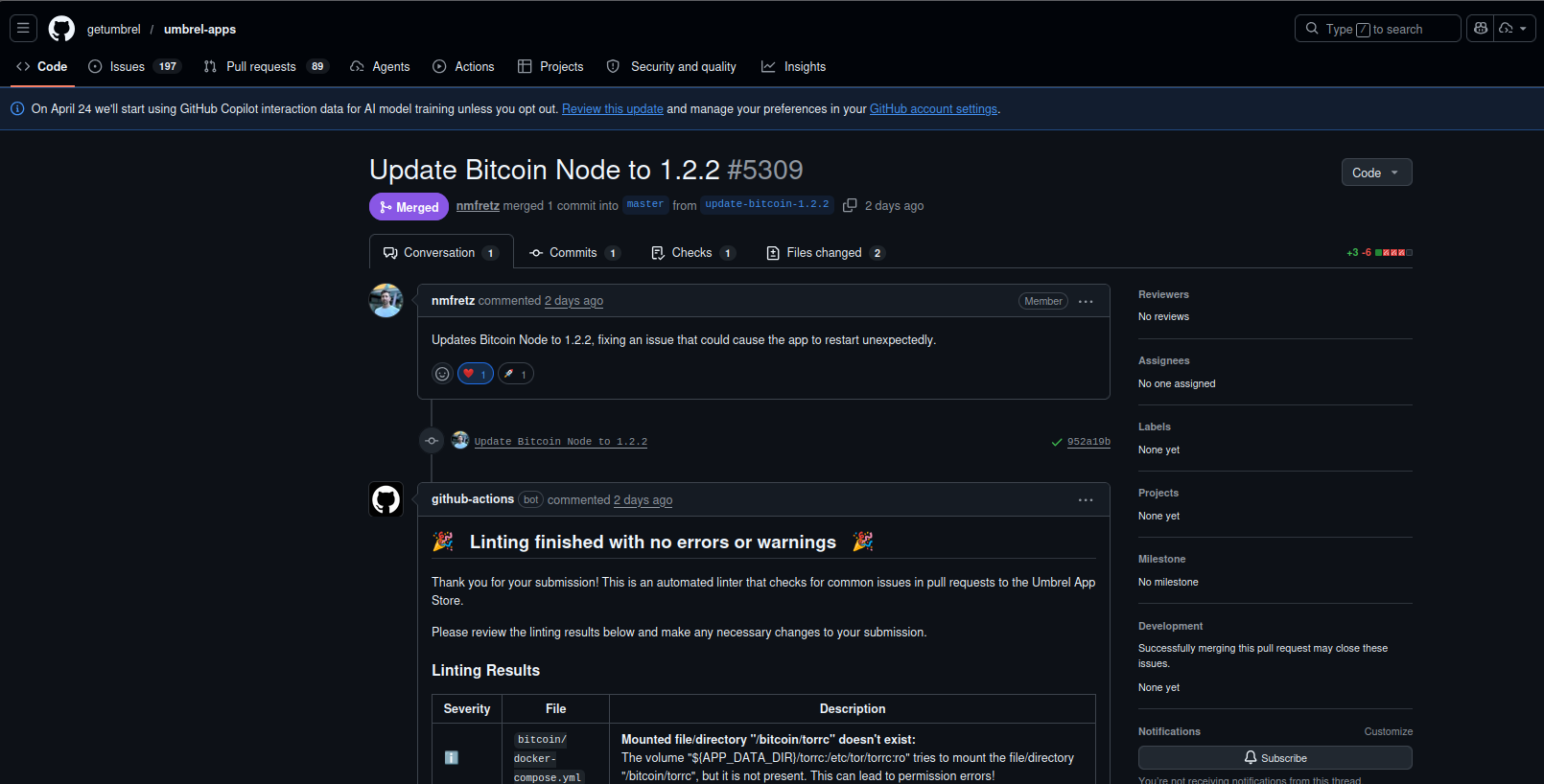
The Result: PR #5309 Merged and v1.2.2 Released
Bug report submitted
Detailed report filed against getumbrel/umbrel-apps with a full evidence log, elimination matrix, and suspected root cause in the Tor configuration layer. The report cited the consistent ~25-hour cycle and the torrc volume mount as the prime candidate — log summary details and timestamps, not raw output for the team to scrub.
nmfretz acknowledges and opens PR #5309
Umbrel core developer nmfretz opens PR #5309 — "Updates Bitcoin Node to 1.2.2, fixing an issue that could cause the app to restart unexpectedly." The confirmed root cause: ${APP_DATA_DIR}/torrc:/etc/tor/torrc:ro in docker-compose.yml mounted a torrc file that didn't exist, causing Tor permission errors and the restart cycle. 2 files changed, +3 −6.
Official v1.2.2 released
umbrel-bitcoin v1.2.2 ships with the Tor connectivity fix. Thousands of nodes globally receive the patch. The 24–36 hour disconnect cycle is resolved.
A bug report filed late at night. A confirmed root cause by morning. An official release the same day. That kind of turnaround is genuinely uncommon for any open-source project. What it reflects is straightforward: the team at Umbrel is taking their applications seriously. There is a real engineering team behind the scenes — even in a stack built around Tor's privacy layers, where the infrastructure is intentionally obscured — and they acted on actionable information quickly. That responsiveness isn't something you can manufacture. It's the result of developers who care about the quality of what they ship. The structured report made it possible for them to move without back-and-forth. That's the practical takeaway: signal over noise, a clear summary with timestamps and an elimination log, and the right question framed precisely — that's what gives a team like this something to work with.
₿ Network-scale impact: Tor disconnect cycles on Bitcoin nodes affect the peer graph — nodes that regularly drop connections become less reliable routing targets for both payment channels and block propagation. Across thousands of nodes experiencing the same pattern, this creates measurable degradation in network graph stability. The conservative estimate of financial impact (disrupted channel routing, forced reconnects, missed routing fees) runs into the thousands of dollars across affected operators.
The Repeatable Methodology — Applied to Any Node Issue
The Bitcoin Tor case study is one instance of a general debugging framework. The same approach works for any Umbrel stability issue — Lightning routing failures, sync stalls, Electrs index corruption, disk pressure warnings:
-
Open a new markdown session file immediately
Name it with the date and symptom:
2026-04-01-umbrel-tor-disconnects.md. This is your evidence chain from day one. Every observation, timestamp, and hypothesis goes here. -
Read everything before touching anything
Collect all relevant logs. Feed them to AI. Ask for pattern identification, not solutions. Your first three sessions should produce zero config changes.
-
Isolate variables one at a time with 48-hour windows
Stop one app or change one variable per observation window. Document the result immediately. If the symptom persists, that variable is not the cause.
-
Build the predictability test
If you understand the pattern, you should be able to predict the next event. If you can predict it, you have a working hypothesis. If not, keep collecting data.
-
Rotate AI models at the synthesis stage
Once you have 7+ days of evidence, run your full session file through two different models independently. Cross-validate their hypotheses. Consensus increases confidence.
-
Escalate through proper channels with your full evidence
GitHub issues, Umbrel community forums, or Lightning developer channels. Let AI draft the report. Because you did the work, the report is actionable — not a vague symptom description.
₿ Apply This Methodology to Your Node
Download the session template, follow the three-phase framework, and let AI do the heavy lifting on log analysis. The same systematic approach that produced the v1.2.2 fix works on any stability issue.
View PR #5309 on GitHub →